AI tools for missing pages
Related Tools:
404 Not Found Assistant
The website is a simple and straightforward tool that informs users when they encounter a 404 error page, indicating that the requested page is not found. It serves as a notification system to guide users back to the main website or homepage. The tool helps in enhancing user experience by providing clear feedback and direction in case of missing pages.

404 Error Page
The website page displays a 'Not found (404)' error message, indicating that the requested page does not exist on the server. This error message is commonly encountered when a user tries to access a webpage that has been removed or moved. The '404' error is a standard HTTP status code that informs users that the server could not find the requested page. Users may encounter this message due to mistyped URLs, broken links, or website restructuring.
RivalFlow AI by SpyFu Solutions
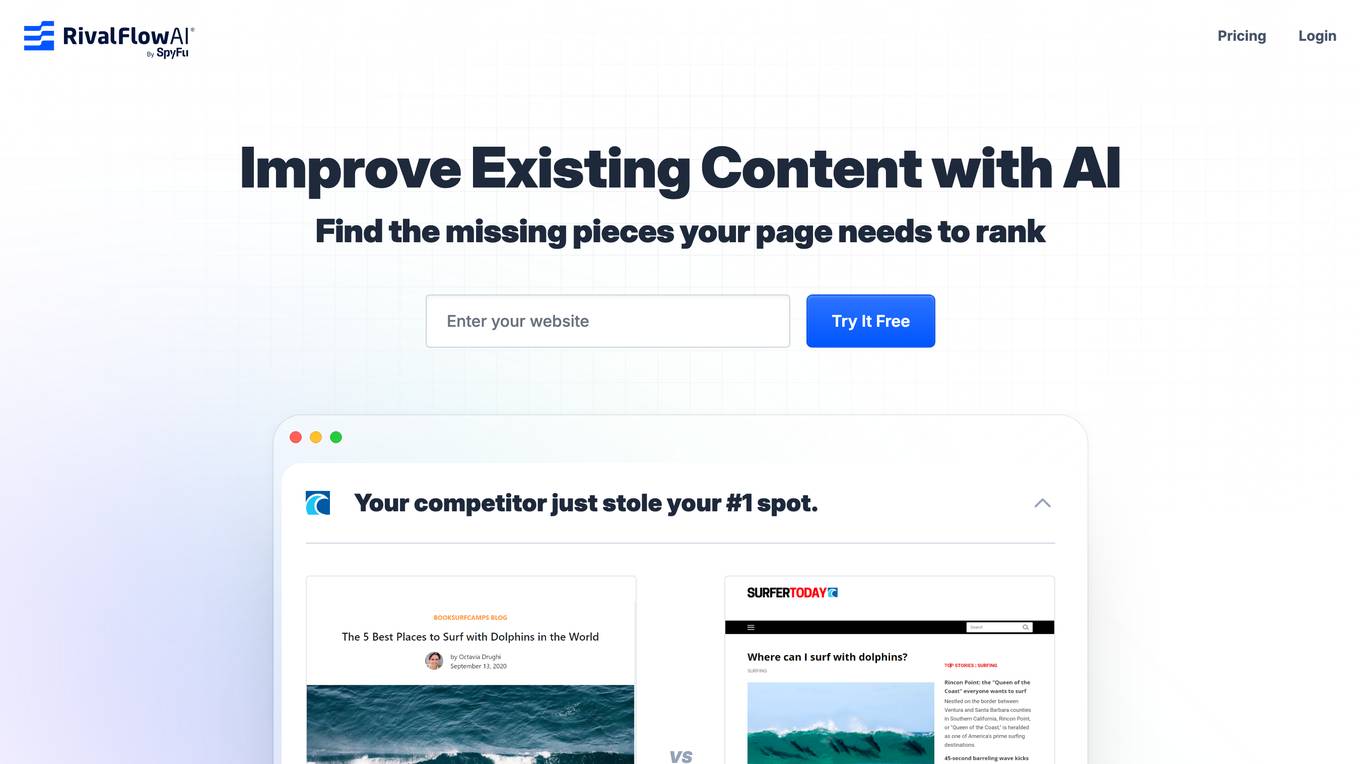
RivalFlow AI by SpyFu Solutions is an AI-powered content optimization tool designed to help agencies, freelancers, and affiliates improve their SEO content to outrank competitors. The tool provides recommendations for page updates, offers ready-to-paste improvements, and shows users where to insert new content. RivalFlow automates ongoing content improvement, allowing users to elevate their client strategy and achieve higher SEO ranks in just 10 days. The tool is Google-approved and aims to enhance user experience and SEO performance.
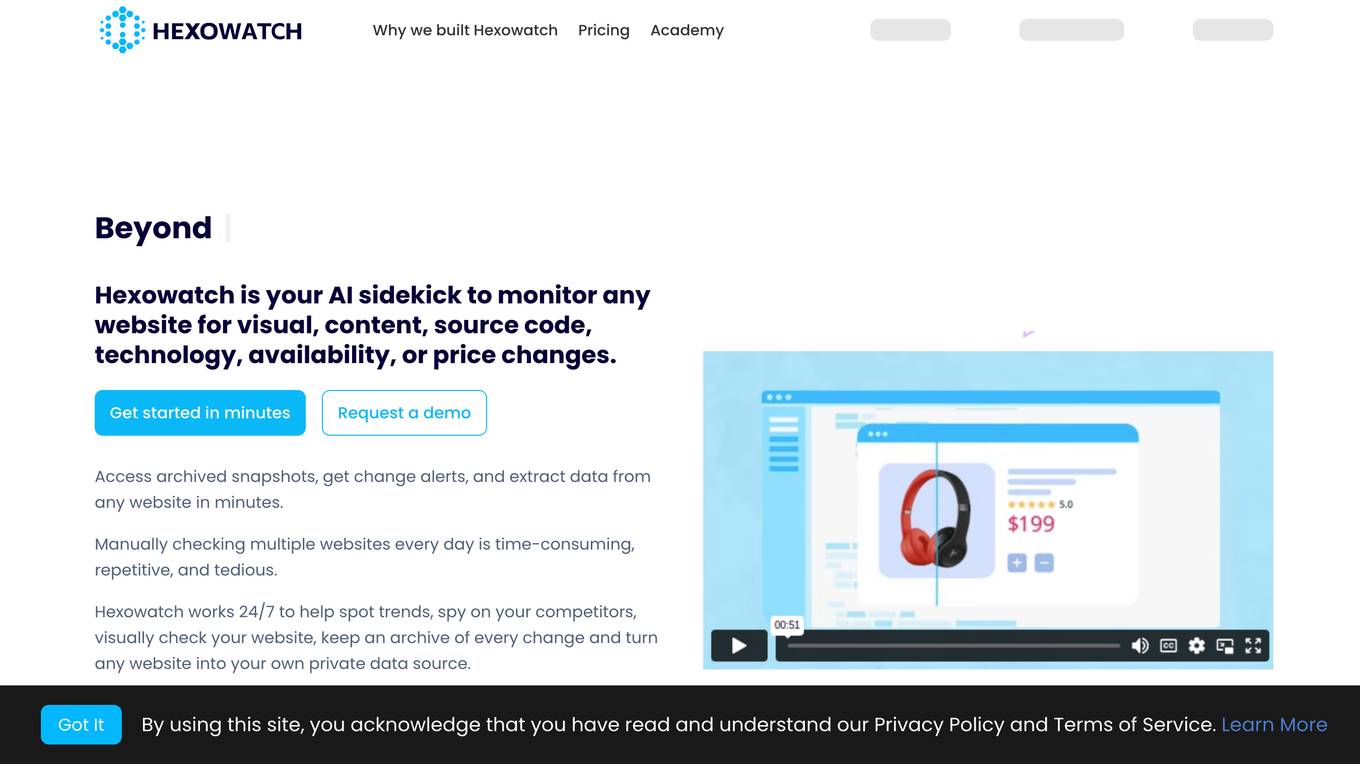
Hexowatch
Hexowatch is an AI-powered website monitoring and archiving tool that helps businesses track changes to any website, including visual, content, source code, technology, availability, or price changes. It provides detailed change reports, archives snapshots of pages, and offers side-by-side comparisons and diff reports to highlight changes. Hexowatch also allows users to access monitored data fields as a downloadable CSV file, Google Sheet, RSS feed, or sync any update via Zapier to over 2000 different applications.

404 Error Page
The website displays a '404 - Page not found' error message indicating that the requested page does not exist or has been moved. It is a common error message encountered when a user tries to access a webpage that is unavailable. The message serves to inform the user that the desired content is not accessible at the moment.
404 Error Page
The website displays a '404 - Page not found' error message, indicating that the requested page does not exist or has been moved. It seems to be a generic error page that users encounter when trying to access a non-existent or relocated webpage.
404 Error Page
The website is a simple error page indicating that the requested page is not found. It is a standard HTTP 404 error page that informs users that the page they are trying to access does not exist or has been moved. The 404 error is a common response code that web servers use to indicate that the client was able to communicate with the server, but the server could not find what was requested.

404 Error Page
The website is a simple error page displaying '404 Page not found'. It seems that the user has reached a page that does not exist on the website. The page is likely a default error message indicating that the requested page could not be found on the server.

Railway Station Error Page
The website page displays a '404 Not Found' error message, indicating that the requested page or resource is not available. It suggests checking network settings and domain provisioning. The message humorously likens the situation to a train not arriving at a station, prompting visitors to inform the site owner of the issue. The page includes a unique Request ID: AIor7PNUR7mzicZ08Zg6wQ_98031763 and a link to 'Go to Railway'.
Not Found
The website provides a simple and concise message stating 'Not Found'. It appears that the page or content being searched for is not available on the website. The website may be experiencing technical issues or the content may have been removed or relocated. Users are advised to check the URL for any errors or try searching for the desired content using the website's search function.

Dropy.AI
Dropy.AI is an AI-powered dropshipping tool designed to revolutionize e-commerce success. It offers a comprehensive suite of features, including AI-assisted store building, product sourcing, social media tools, and competitor analysis. With a focus on efficiency and profitability, Dropy.AI aims to empower entrepreneurs to scale their businesses with ease and stay ahead in the competitive e-commerce landscape.
inpilot
inpilot is an AI-powered platform designed to enhance content creation and management on LinkedIn. It offers a range of features such as AI-assisted writing, AI-generated posts, scheduling calendar, ideas management, statistics, and network management. The tool aims to streamline the content creation process, making it faster, more efficient, and enjoyable for users. With a focus on speed, privacy, and ease of use, inpilot provides users with a comprehensive solution to grow their LinkedIn network and achieve their business or career goals.
re:tune
re:tune is a no-code AI app solution that provides everything you need to transform your business with AI, from custom chatbots to autonomous agents. With re:tune, you can build chatbots for any use case, connect any data source, and integrate with all your favorite tools and platforms. re:tune is the missing platform to build your AI apps.
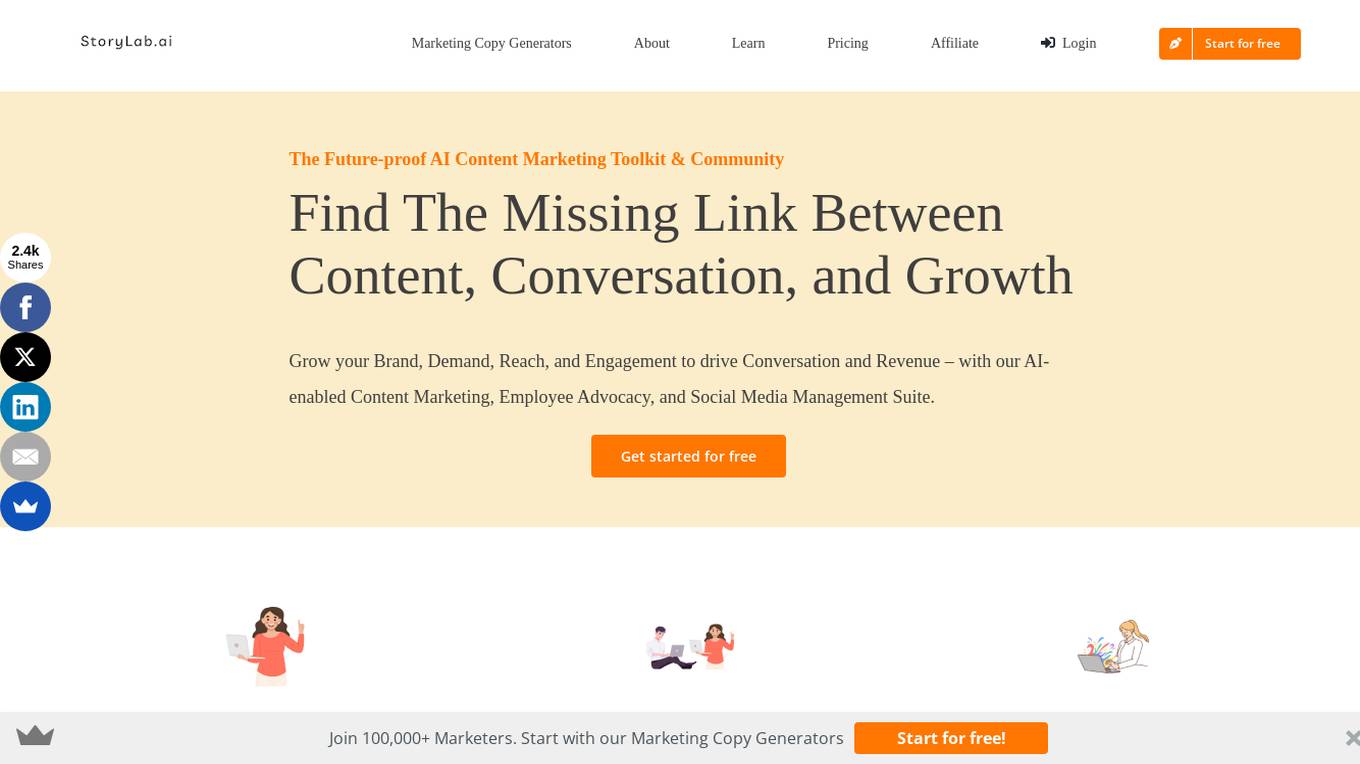
StoryLab.ai
StoryLab.ai is an AI-powered content marketing platform that helps businesses create high-quality content, engage with their audience, and drive growth. The platform offers a range of tools and resources, including AI-powered content generators, social media management tools, and educational resources. StoryLab.ai is designed to help businesses of all sizes create better content, reach a wider audience, and achieve their marketing goals.
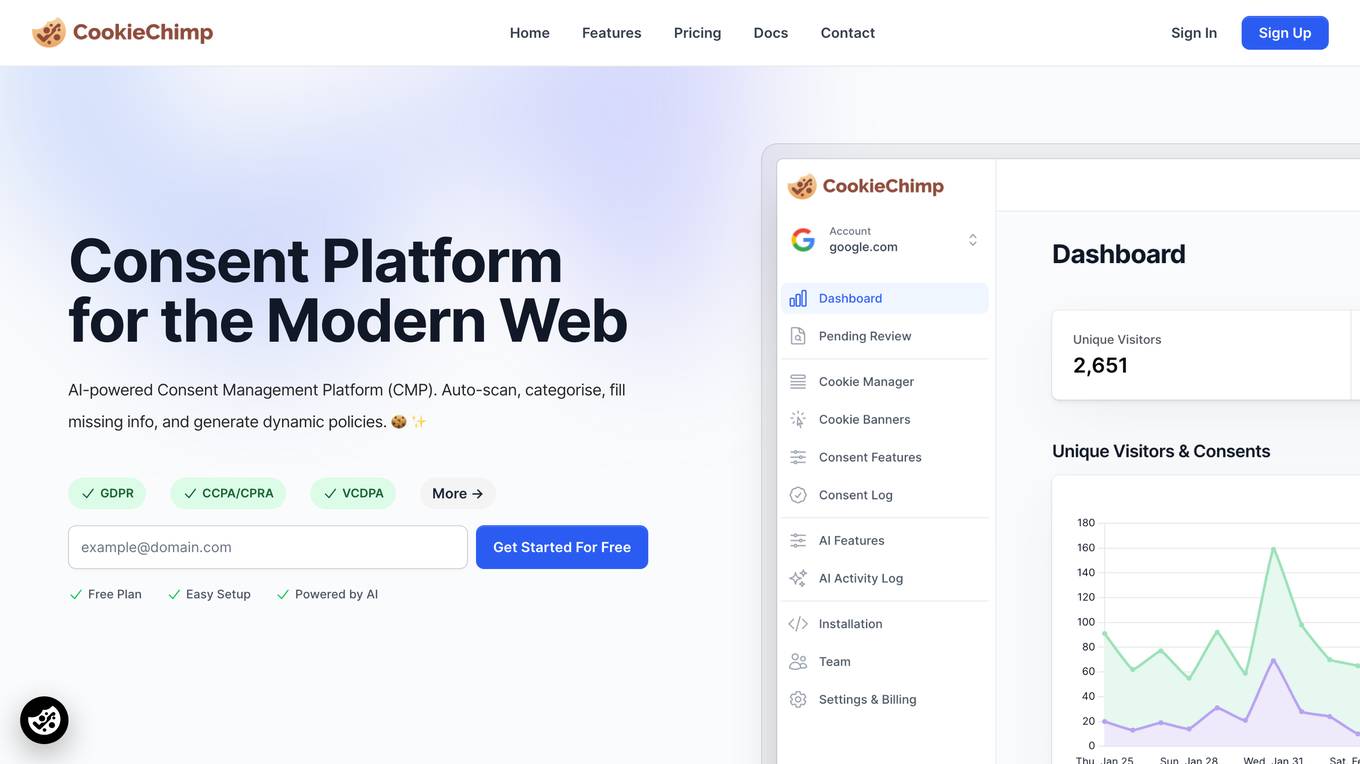
CookieChimp
CookieChimp is a modern consent management platform designed to help websites effortlessly collect user consent for 3rd party services while ensuring compliance with various privacy standards such as GDPR, CCPA, TCF 2.2, and Google Consent Mode. The platform offers features like dashboard monitoring, automated cookie scanning, customizable consent banners, integrations with CRM and marketing tools, global compliance solutions, robust consent logging, and AI-powered efficiency. CookieChimp is trusted by modern companies for its user-friendly interface, valuable insights, and quick setup process.
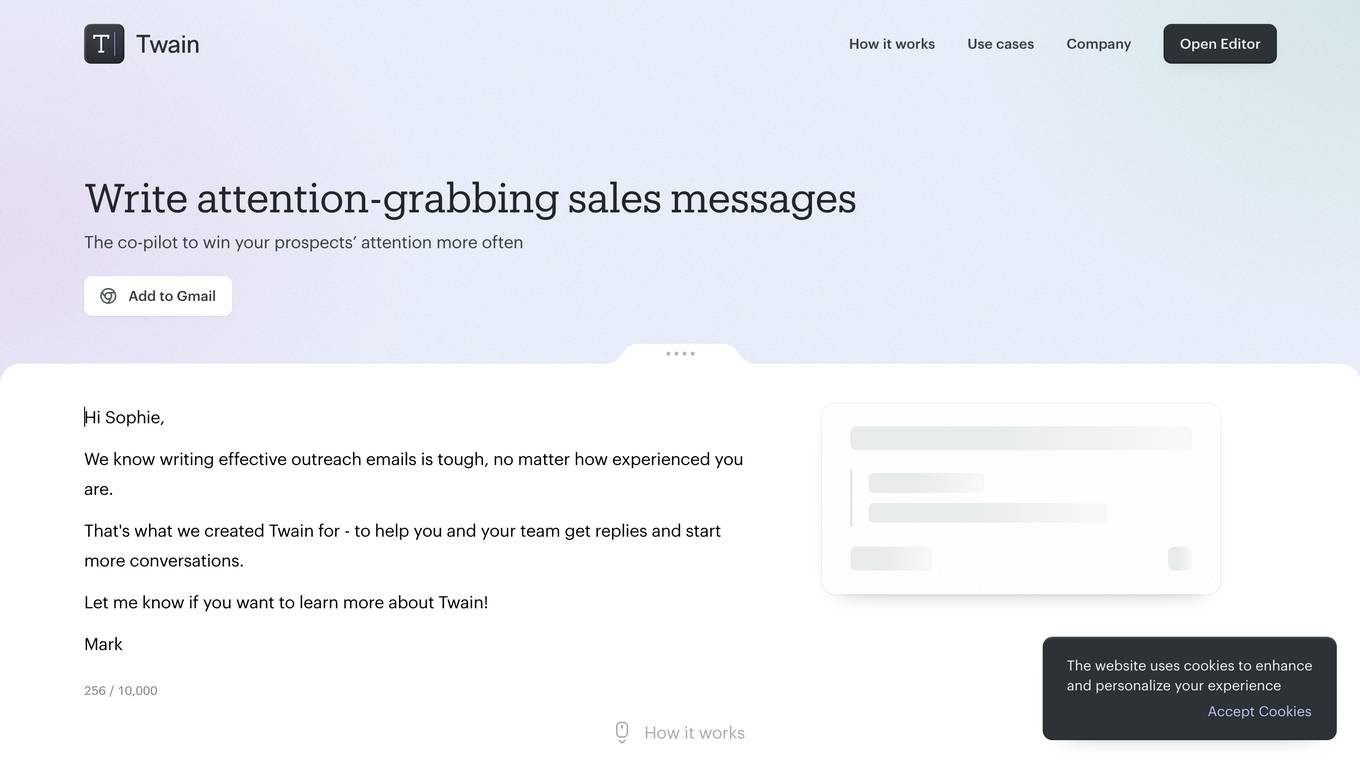
Twain
Twain is an AI-powered communication assistant designed to help users write more effective outreach messages. It provides real-time feedback and suggestions based on best practices, helping users improve the clarity, persuasiveness, and response rates of their emails. Twain is particularly useful for sales professionals, recruiters, and anyone else who needs to write persuasive and engaging outreach messages.
Missing Cluster Identification Program
I analyze and integrate missing clusters in data for coherent structuring.
PixarStyle Yourself
Without missing a single detail, this GPT masterfully creates Pixar-style images from any photo [Updated version].

Detective Virtuel
Un détective privé qualifié, parle couramment le français et habile dans les enquêtes en ligne. GPTseek.com=G0LWETXGGL
Calm Navigator
Professional coach guiding users to overcome FOMO with practical advice and support.
Detective Sherlock
Your AI Detective for piecing together puzzles and solving any mystery.
Excuse Genius - Get Out Of Going To Work!
Generates believable, ethical excuses for not attending work.

DataQualityGuardian
A GPT-powered assistant specializing in data validation and quality checks for various datasets.

Raven's Progressive Matrices Test
Provides Raven's Progressive Matrices test with explanations and calculates your IQ score.

ChatXGB
GPT chatbot that helps you with technical questions related to XGBoost algorithm and library

Sherlock Holmes
Sherlock Holmes-inspired detective with keen observation and analytical skills.


pdr_ai_v2
pdr_ai_v2 is a Python library for implementing machine learning algorithms and models. It provides a wide range of tools and functionalities for data preprocessing, model training, evaluation, and deployment. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists. With pdr_ai_v2, users can easily build and deploy machine learning models for various applications, such as classification, regression, clustering, and more.

growi
GROWI is a collaborative wiki platform that allows users to create hierarchical pages with markdown, edit simultaneously with multiple people, and support authentication with LDAP/Active Directory, OAuth, and SAML. It also integrates with Slack/Mattermost, IFTTT, and allows for plugin customization. GROWI is Docker and Docker Compose ready, supports multiple sites, HTTPS with Let's Encrypt proxy integration, and offers migration guides for on-premise installations. The tool is built with Node.js, npm, pnpm, Turborepo, and requires MongoDB, with optional dependencies on Redis and ElasticSearch for full-text search functionality.
oxylabs-mcp
The Oxylabs MCP Server acts as a bridge between AI models and the web, providing clean, structured data from any site. It enables scraping of URLs, rendering JavaScript-heavy pages, content extraction for AI use, bypassing anti-scraping measures, and accessing geo-restricted web data from 195+ countries. The implementation utilizes the Model Context Protocol (MCP) to facilitate secure interactions between AI assistants and web content. Key features include scraping content from any site, automatic data cleaning and conversion, bypassing blocks and geo-restrictions, flexible setup with cross-platform support, and built-in error handling and request management.
feedgen
FeedGen is an open-source tool that uses Google Cloud's state-of-the-art Large Language Models (LLMs) to improve product titles, generate more comprehensive descriptions, and fill missing attributes in product feeds. It helps merchants and advertisers surface and fix quality issues in their feeds using Generative AI in a simple and configurable way. The tool relies on GCP's Vertex AI API to provide both zero-shot and few-shot inference capabilities on GCP's foundational LLMs. With few-shot prompting, users can customize the model's responses towards their own data, achieving higher quality and more consistent output. FeedGen is an Apps Script based application that runs as an HTML sidebar in Google Sheets, allowing users to optimize their feeds with ease.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.
json_repair
This simple package can be used to fix an invalid json string. To know all cases in which this package will work, check out the unit test. Inspired by https://github.com/josdejong/jsonrepair Motivation Some LLMs are a bit iffy when it comes to returning well formed JSON data, sometimes they skip a parentheses and sometimes they add some words in it, because that's what an LLM does. Luckily, the mistakes LLMs make are simple enough to be fixed without destroying the content. I searched for a lightweight python package that was able to reliably fix this problem but couldn't find any. So I wrote one How to use from json_repair import repair_json good_json_string = repair_json(bad_json_string) # If the string was super broken this will return an empty string You can use this library to completely replace `json.loads()`: import json_repair decoded_object = json_repair.loads(json_string) or just import json_repair decoded_object = json_repair.repair_json(json_string, return_objects=True) Read json from a file or file descriptor JSON repair provides also a drop-in replacement for `json.load()`: import json_repair try: file_descriptor = open(fname, 'rb') except OSError: ... with file_descriptor: decoded_object = json_repair.load(file_descriptor) and another method to read from a file: import json_repair try: decoded_object = json_repair.from_file(json_file) except OSError: ... except IOError: ... Keep in mind that the library will not catch any IO-related exception and those will need to be managed by you Performance considerations If you find this library too slow because is using `json.loads()` you can skip that by passing `skip_json_loads=True` to `repair_json`. Like: from json_repair import repair_json good_json_string = repair_json(bad_json_string, skip_json_loads=True) I made a choice of not using any fast json library to avoid having any external dependency, so that anybody can use it regardless of their stack. Some rules of thumb to use: - Setting `return_objects=True` will always be faster because the parser returns an object already and it doesn't have serialize that object to JSON - `skip_json_loads` is faster only if you 100% know that the string is not a valid JSON - If you are having issues with escaping pass the string as **raw** string like: `r"string with escaping\"" Adding to requirements Please pin this library only on the major version! We use TDD and strict semantic versioning, there will be frequent updates and no breaking changes in minor and patch versions. To ensure that you only pin the major version of this library in your `requirements.txt`, specify the package name followed by the major version and a wildcard for minor and patch versions. For example: json_repair==0.* In this example, any version that starts with `0.` will be acceptable, allowing for updates on minor and patch versions. How it works This module will parse the JSON file following the BNF definition: <json> ::= <primitive> | <container> <primitive> ::= <number> | <string> | <boolean> ; Where: ; <number> is a valid real number expressed in one of a number of given formats ; <string> is a string of valid characters enclosed in quotes ; <boolean> is one of the literal strings 'true', 'false', or 'null' (unquoted) <container> ::= <object> | <array> <array> ::= '[' [ <json> *(', ' <json>) ] ']' ; A sequence of JSON values separated by commas <object> ::= '{' [ <member> *(', ' <member>) ] '}' ; A sequence of 'members' <member> ::= <string> ': ' <json> ; A pair consisting of a name, and a JSON value If something is wrong (a missing parantheses or quotes for example) it will use a few simple heuristics to fix the JSON string: - Add the missing parentheses if the parser believes that the array or object should be closed - Quote strings or add missing single quotes - Adjust whitespaces and remove line breaks I am sure some corner cases will be missing, if you have examples please open an issue or even better push a PR How to develop Just create a virtual environment with `requirements.txt`, the setup uses pre-commit to make sure all tests are run. Make sure that the Github Actions running after pushing a new commit don't fail as well. How to release You will need owner access to this repository - Edit `pyproject.toml` and update the version number appropriately using `semver` notation - **Commit and push all changes to the repository before continuing or the next steps will fail** - Run `python -m build` - Create a new release in Github, making sure to tag all the issues solved and contributors. Create the new tag, same as the one in the build configuration - Once the release is created, a new Github Actions workflow will start to publish on Pypi, make sure it didn't fail Bonus Content If you need some good Custom Instructions (System Message) to improve your chatbot responses try https://gist.github.com/mangiucugna/7ec015c4266df11be8aa510be0110fe4 Star History [Star History Chart](https://api.star-history.com/svg?repos=mangiucugna/json_repair&type=Date)

qb
QANTA is a system and dataset for question answering tasks. It provides a script to download datasets, preprocesses questions, and matches them with Wikipedia pages. The system includes various datasets, training, dev, and test data in JSON and SQLite formats. Dependencies include Python 3.6, `click`, and NLTK models. Elastic Search 5.6 is needed for the Guesser component. Configuration is managed through environment variables and YAML files. QANTA supports multiple guesser implementations that can be enabled/disabled. Running QANTA involves using `cli.py` and Luigi pipelines. The system accesses raw Wikipedia dumps for data processing. The QANTA ID numbering scheme categorizes datasets based on events and competitions.

GraphLLM
GraphLLM is a graph-based framework designed to process data using LLMs. It offers a set of tools including a web scraper, PDF parser, YouTube subtitles downloader, Python sandbox, and TTS engine. The framework provides a GUI for building and debugging graphs with advanced features like loops, conditionals, parallel execution, streaming of results, hierarchical graphs, external tool integration, and dynamic scheduling. GraphLLM is a low-level framework that gives users full control over the raw prompt and output of models, with a steeper learning curve. It is tested with llama70b and qwen 32b, under heavy development with breaking changes expected.
glimpse
Glimpse is a blazingly fast tool for peeking at codebases, offering features like fast parallel file processing, tree-view of codebase structure, source code content viewing, token counting with multiple backends, configurable defaults, clipboard support, customizable file type detection, .gitignore respect, web content processing with Markdown conversion, Git repository support, and URL traversal with configurable depth. It supports token counting using Tiktoken or HuggingFace tokenizer backends, helping estimate context window usage for large language models. Glimpse can process local directories, multiple files, Git repositories, web pages, and convert content to Markdown. It offers various options for customization and configuration, including file type inclusions/exclusions, token counting settings, URL processing settings, and default exclude patterns. Glimpse is suitable for developers and data scientists looking to analyze codebases, estimate token counts, and process web content efficiently.
airbase
Airbase is a Maven project management tool that provides a parent pom structure and conventions for defining new projects. It includes guidelines for project pom structure, deployment to Maven Central, project build and checkers, well-known dependencies, and other properties. Airbase helps in enforcing build configurations, organizing project pom files, and running various checkers to catch problems early in the build process. It also offers default properties that can be overridden in the project pom.
llmware
LLMWare is a framework for quickly developing LLM-based applications including Retrieval Augmented Generation (RAG) and Multi-Step Orchestration of Agent Workflows. This project provides a comprehensive set of tools that anyone can use - from a beginner to the most sophisticated AI developer - to rapidly build industrial-grade, knowledge-based enterprise LLM applications. Our specific focus is on making it easy to integrate open source small specialized models and connecting enterprise knowledge safely and securely.
n8n-docs
n8n is an extendable workflow automation tool that enables you to connect anything to everything. It is open-source and can be self-hosted or used as a service. n8n provides a visual interface for creating workflows, which can be used to automate tasks such as data integration, data transformation, and data analysis. n8n also includes a library of pre-built nodes that can be used to connect to a variety of applications and services. This makes it easy to create complex workflows without having to write any code.

Mira
Mira is an agentic AI library designed for automating company research by gathering information from various sources like company websites, LinkedIn profiles, and Google Search. It utilizes a multi-agent architecture to collect and merge data points into a structured profile with confidence scores and clear source attribution. The core library is framework-agnostic and can be integrated into applications, pipelines, or custom workflows. Mira offers features such as real-time progress events, confidence scoring, company criteria matching, and built-in services for data gathering. The tool is suitable for users looking to streamline company research processes and enhance data collection efficiency.
sample-apps
Vespa is an open-source search and AI engine that provides a unified platform for building and deploying search and AI applications. Vespa sample applications showcase various use cases and features of Vespa, including basic search, recommendation, semantic search, image search, text ranking, e-commerce search, question answering, search-as-you-type, and ML inference serving.
ai-notes
Notes on AI state of the art, with a focus on generative and large language models. These are the "raw materials" for the https://lspace.swyx.io/ newsletter. This repo used to be called https://github.com/sw-yx/prompt-eng, but was renamed because Prompt Engineering is Overhyped. This is now an AI Engineering notes repo.


cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.
WritingAIPaper
WritingAIPaper is a comprehensive guide for beginners on crafting AI conference papers. It covers topics like paper structure, core ideas, framework construction, result analysis, and introduction writing. The guide aims to help novices navigate the complexities of academic writing and contribute to the field with clarity and confidence. It also provides tips on readability improvement, logical strength, defensibility, confusion time reduction, and information density increase. The appendix includes sections on AI paper production, a checklist for final hours, common negative review comments, and advice on dealing with paper rejection.